Achieving True Data Interoperability with BigLake and Apache Iceberg
Authors:
Bhaskaran Kannan - Director, Data Engineering
Kamalesh B - Senior Data Engineer
Ruchit Furia - Senior Solutions Consultant, Cloud Platform Modernization
Why the Future Belongs to Open, Interoperable Data
The next decade of AI and analytics will be won by organizations that embrace open, interoperable data architectures. In today's digital economy, your ability to unify, govern, and activate data across multiple engines isn't just a technical advantage—it's a business-critical differentiator. Yet too often, data remains locked in proprietary systems, creating costly silos and stifling innovation.
The solution lies in open standards. This is where Apache Iceberg, an open table format, combined with Google Cloud's BigLake, a unified storage engine, empowers enterprises to achieve true data interoperability. Together, they unlock a multi-engine strategy that supports modern analytics, AI-ready platforms, and future-proof architectures.
This blog explores why enterprises are pivoting to open lakehouse formats, how BigLake and Iceberg work together, and what this means for your business, your AI strategy, and your bottom line.
Why Open Formats Matter: The Enterprise Pivot to Apache Iceberg
For years, enterprises were tied to proprietary formats and analytics engines. This created vendor lock-in, forced redundant data copies, and inflated costs. Apache Iceberg solves this challenge by acting as a universal adapter for data lakes.
Iceberg doesn't store data itself—it manages metadata on top of open file formats like Parquet, ORC, and Avro, enabling consistent, high-performance access across tools.
Key benefits of Apache Iceberg include:
- Schema Evolution: Easily add, rename, or drop columns without rewriting massive datasets. This agility is crucial as business requirements change.
- Time Travel and Versioning: Query historical versions of your data effortlessly for audits, reproducing ML model results, or recovering from errors.
- Concurrent Writes: Multiple engines can safely write to the same table simultaneously without data corruption, thanks to optimistic concurrency control.
- Hidden Partitioning: Iceberg handles data partitioning automatically in the background, freeing data engineers from a complex and error-prone task while maintaining fast query performance.
By adopting an open format like Iceberg, enterprises are fundamentally future-proofing their data strategy, ensuring their most valuable asset remains accessible and independent of any single tool or vendor.
BigLake and Iceberg: The Power Couple for Interoperability
While Iceberg provides the open format, BigLake provides the governance and control layer.
BigLake acts as a unified storage engine that extends the governance and fine-grained security controls of BigQuery to data stored in open formats on cloud storage. When you create a BigLake Iceberg table, you're not moving data into a warehouse. Instead, you're creating a managed, governed pointer to your Iceberg-formatted data living in Google Cloud Storage.
This architecture enables a true multi-engine strategy. Your data team can use BigQuery for lightning-fast SQL analytics, data scientists can use Spark within Dataproc or Vertex AI for machine learning model training, and data engineers can use open-source engines like Trino or Flink or other proprietary warehouses like Snowflake for specific processing tasks - all operating on the exact same copy of the data.
How It Works: Multi-Engine Architecture in Action:
- Single Source of Truth: Your data resides in an open format (Iceberg) on Google Cloud Storage.
- Unified Governance: BigLake provides a centralized place to manage security policies, data masking, row-level security, and column-level access controls.
- Engine-Agnostic Access: Any supported engine (BigQuery, Spark, Presto, Snowflake, Databricks, etc.) can read to the BigLake Iceberg tables, with all governance policies enforced consistently.
This eliminates redundant data copies, reduces storage costs, and ensures every team is working from the same, up-to-date information.
Architecture and High-level Implementation Steps for demonstration:
At the core of this architecture we have:
- Storage Layer: Iceberg Data + Metadata stored in Google Cloud Storage.
- Synchronization: Pub/Sub provides automatic refresh, enabling near real-time synchronization. It sends notifications to Snowflake whenever a change is made to the Iceberg table, triggering the refresh.
- Compute Engines: BigQuery, BigLake, Apache Spark, and Snowflake consume the same Iceberg data.
- Users: Access a single, consistent source of truth across platforms.
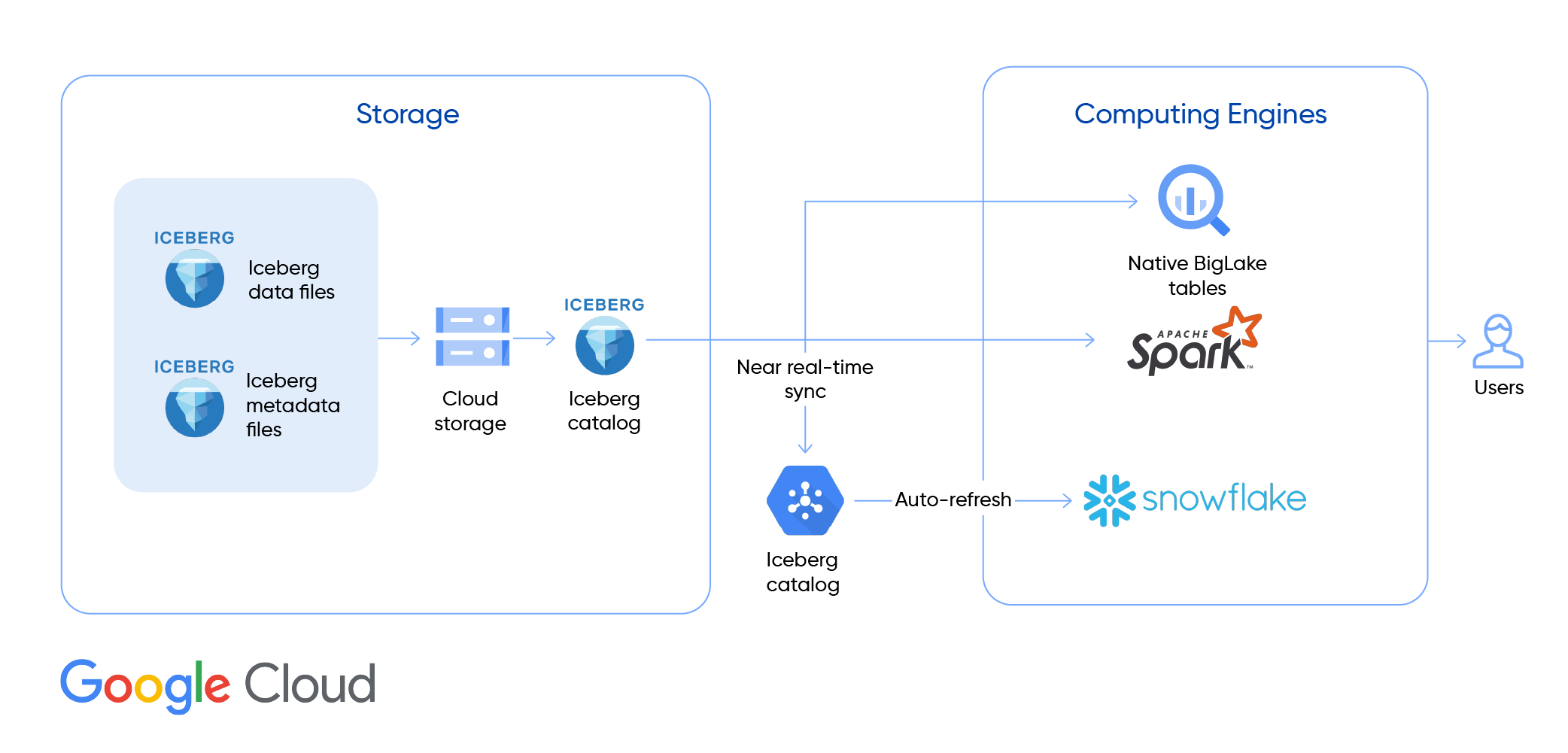
Key Steps in Building the Interoperable Platform
Here are the steps to make BigQuery and Snowflake seamlessly share data using Apache Iceberg and Pub/Sub.
See this in action below.
- Create an External Data Source Connection (BigQuery → GCS)
This connection bridges BigQuery with Google Cloud Storage for managed Iceberg tables.
bq --project_id=your-project-id mk --connection \ --connection_type=CLOUD_RESOURCE \ --location=us-central1 \ --display_name="blmt-connection" \ --description="BigLake connection to GCS" \ blmt-connection - Create an Iceberg Table in BigQuery BigLake
CREATE OR REPLACE TABLE `blmt_dataset.driver` ( driver_id INT64, driver_name STRING, driver_email_address STRING, driver_dob DATE ) CLUSTER BY driver_id WITH CONNECTION `us-central1.blmt-connection` OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://blmt-snowflake-sharing/driver' ); - Set Up Pub/Sub for Change Notifications
# Create Pub/Sub topic gcloud pubsub topics create my-gcs-topic # Create subscription gcloud pubsub subscriptions create my-gcs-sub --topic=my-gcs-topic # Enable GCS notifications gsutil notification create -t my-gcs-topic -f json gs://blmt-snowflake-sharing - Create Snowflake Notification Integration
CREATE NOTIFICATION INTEGRATION my_notification_int TYPE = QUEUE NOTIFICATION_PROVIDER = GCP_PUBSUB ENABLED = TRUE GCP_PUBSUB_SUBSCRIPTION_NAME = 'projects/your-project-id/subscriptions/my-gcs-sub'; - Create External Table in Snowflake with Auto-Refresh
-- Storage integration CREATE STORAGE INTEGRATION my_storage_int TYPE = EXTERNAL_STAGE STORAGE_PROVIDER = 'GCS' ENABLED = TRUE STORAGE_ALLOWED_LOCATIONS = ('gcs://blmt-snowflake-sharing/driver/'); -- Stage definition CREATE STAGE mystage_driver_data URL = 'gcs://blmt-snowflake-sharing/driver/data/' STORAGE_INTEGRATION = my_storage_int FILE_FORMAT = (TYPE = PARQUET); -- External table with auto-refresh CREATE OR REPLACE EXTERNAL TABLE ext_driver_data INTEGRATION = 'MY_NOTIFICATION_INT' WITH LOCATION = @mystage_driver_data FILE_FORMAT = (TYPE = PARQUET) AUTO_REFRESH = TRUE;
Long-Term Strategic Impact
Business Impact:
- Cost Optimization: Use the most cost-effective engine for each workload. Run large-scale ETL with Spark and interactive analytics with BigQuery without paying for two separate storage systems.
- Increased Innovation: Teams can use the best tools for their specific needs, accelerating development cycles and empowering them to experiment without being constrained by a single platform.
- Future-Proofing: As new analytics engines and AI tools emerge, you can easily integrate them into your stack without needing to re-architect your data platform.
Technical Impact:
- Architectural Flexibility: Decouple your compute from your storage, allowing you to scale each independently. This prevents the creation of fragmented data marts and silos.
- Simplified Governance: Centralize data security and access control through BigLake, drastically simplifying the compliance and governance burden.
- Improved Data Quality: With a single source of truth, you eliminate the inconsistencies and quality issues that arise from maintaining multiple data copies.
Conclusion: The Multi-Engine, AI-Ready Future
The future of data is open, interoperable, and AI-ready. With BigLake and Apache Iceberg, enterprises can:
- Break free from vendor lock-in.
- Govern one copy of data across multiple engines.
- Enable AI and analytics workflows that are faster, cheaper, and more reliable.
As data-driven innovation accelerates, the question isn't whether you should adopt an open multi-engine strategy—it's how quickly you can. BigLake + Iceberg is the foundation for next-generation AI, analytics, and agentic workflows.