Beyond the Silo: Choosing the Right External Table Strategy for Your AI-Ready Data Lake

In today's cloud-centric landscape, the core mandate for every enterprise is: access all your data, govern it centrally, and keep costs low. This strategic necessity drives a critical decision for organizations on Google Cloud and Databricks: how to efficiently query petabytes of data residing in low-cost cloud storage (the data lake) without moving it into an expensive data warehouse.
The answer is External Tables—the essential bridge between your high-performance analytics engines and your vast, low-cost data lake. The choice between BigQuery's and Databricks' approach is more than technical; it dictates your future cost optimization, governance posture, and the speed of your AI/ML deployment.
Why External Tables are a Strategic Imperative
External Tables are not just a technical feature; they are a fundamental shift in data strategy that solves three major business pains:
-
Eliminating Data Duplication and Cost Sprawl
The traditional approach demands copying massive datasets from the data lake into a warehouse for analysis, creating two copies of the same data. This is a massive budget drain, resulting in "storage sprawl."
- Strategic Fix: External Tables allow data to stay put in Google Cloud Storage (GCS), slashing redundant storage costs and simplifying the financial audit trail for data storage.
- Business Benefit: Reduced Total Cost of Ownership (TCO) for the data platform.
-
Achieving Real-Time Agility for Decision Making
Waiting for complex Extract, Transform, Load (ETL) pipelines to fully populate a data warehouse table means slow, dated decision-making.
- Strategic Fix: External Tables offer real-time access to the latest data in the lake. There is no ETL latency to wait for, as the tables query the source data directly.
- Business Benefit: Lowest possible latency for accessing the freshest data, ensuring insights are driven by the most current information and supporting operational agility.
-
Unifying Data Access and Boosting Productivity
Data scientists, BI analysts, and data engineers often require specialized tools and code (like Spark programs) to query lake data, creating silos of expertise.
- Strategic Fix: External Tables enable standard SQL access for everyone across disparate data sources.
- Business Benefit: Increased developer productivity and a unified, self-service data culture. Analysts can use familiar tools like BigQuery, while data scientists leverage Databricks, all on the same data.
BigQuery vs. Databricks: A Strategic Decision Matrix
While both platforms achieve the goal of querying external data, their underlying compute architectures lead to significant differences in performance, cost model, and use case suitability.
-
Performance and Compute Architecture (Business Impact)
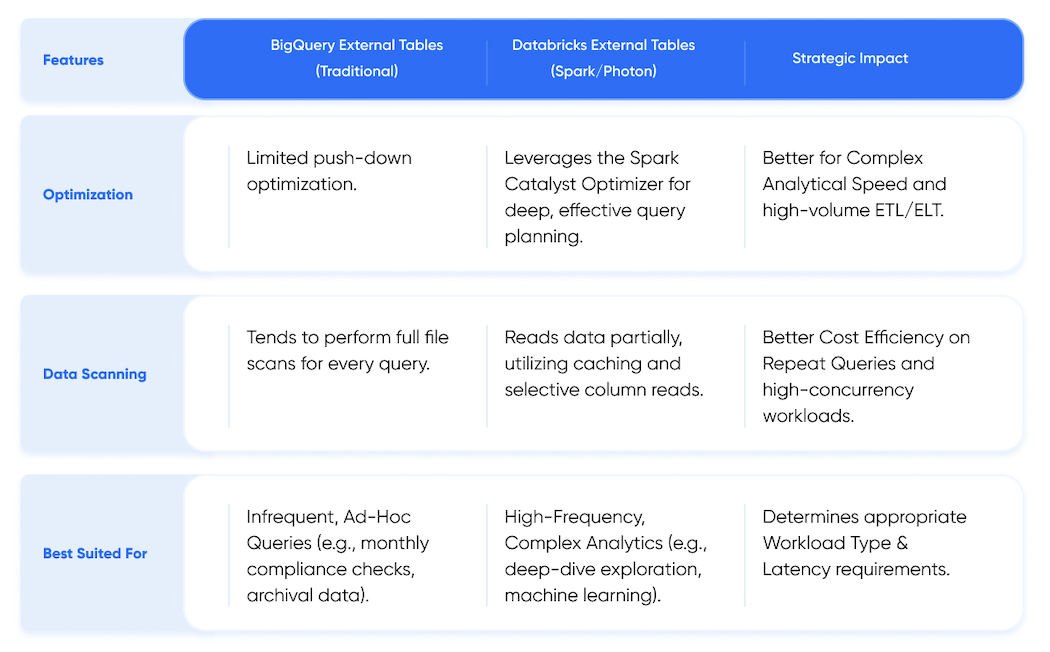
Strategic Insight: For demanding workloads that require high concurrency and complex data manipulation across massive datasets, Databricks (leveraging the distributed Spark/Photon engine) generally offers superior query efficiency. However, the sheer simplicity and zero-management of BigQuery's serverless architecture remain compelling for simpler, less frequent analysis.
-
The Cost Model: Predictability vs. Consumption (Financial Angle)
The financial model is often the ultimate differentiator:

Strategic Insight: If query frequency is extremely low, BigQuery's simple pay-per-scan model is highly cost-effective and easy to budget. For heavy, consistent analytical usage, Databricks' ability to reuse compute and cache data often results in a better long-term TCO once the initial cluster cost is amortized.
Architecture and Performance
The architectural difference explains the cost and performance divergence.
-
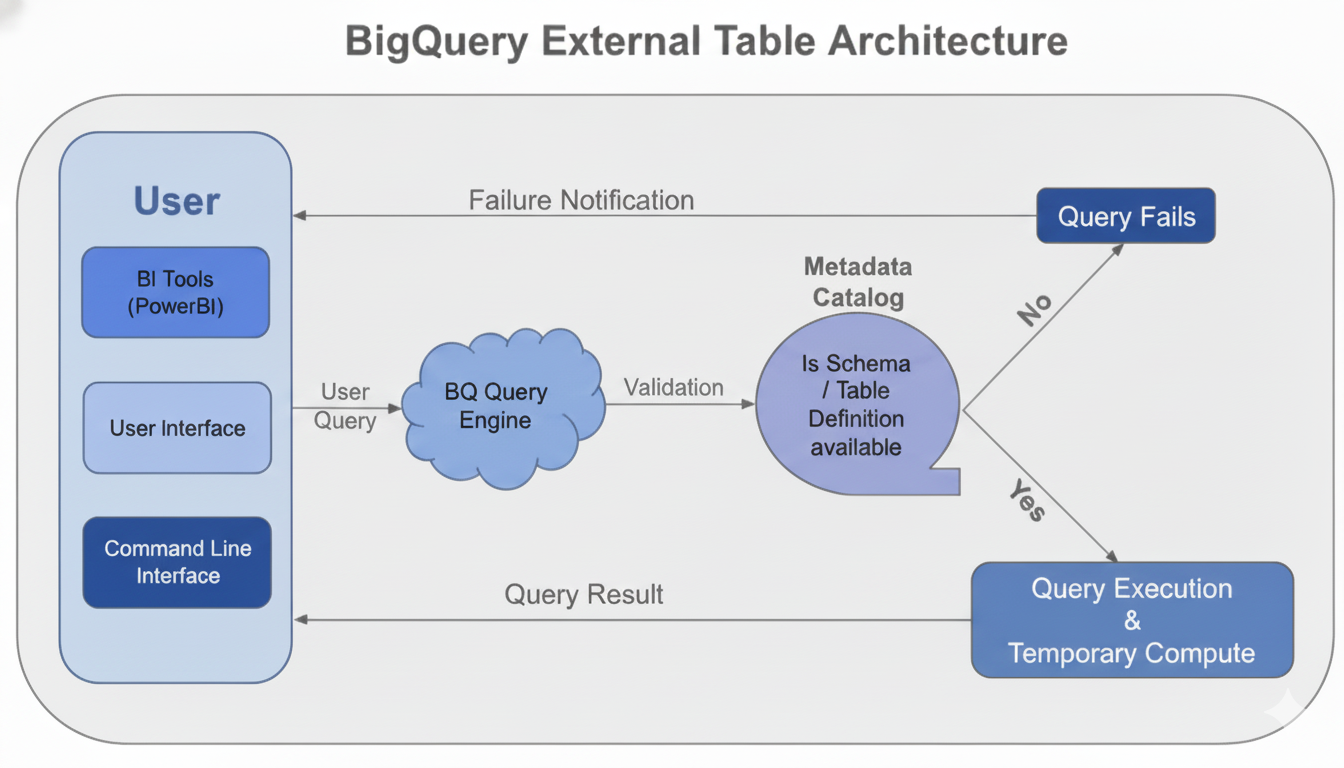
BigQuery External Table Architecture
When a query is fired:
- The BigQuery query engine validates the query and generates an execution plan.
- Optimization is restricted and limited because the data is external.
- The engine generally performs a full scan of the referenced data files in GCS (unless open formats like Parquet/ORC enable some column projection).
- Data is typically not cached at the storage layer, leading to repeated I/O costs and increased latency on subsequent queries.
Technical Performance Limit: The lack of deep optimization and persistent caching means it is inherently less cost-effective and slower for repetitive, high-volume analytical workloads.
-
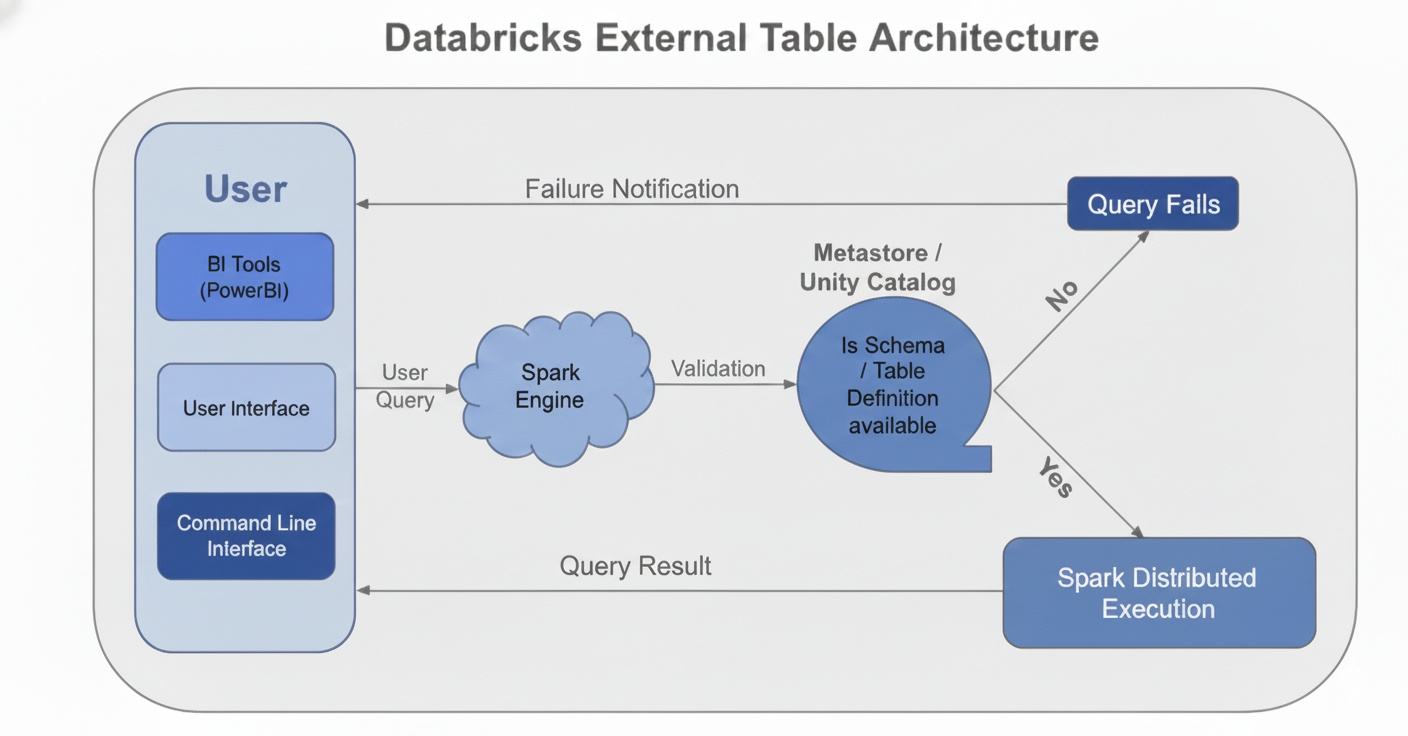
Databricks External Table Architecture
When a query is fired:
- The Spark Engine checks the metadata through the Unity Catalog or Hive Metastore.
- The powerful Spark Catalyst Optimizer generates a highly effective execution plan.
- The distributed Spark/Photon engine fetches the data from GCS in a parallel fashion.
- The engine can read data selectively (column pruning) and pass filters down to the source (filter push-down), avoiding parsing the complete dataset. It also offers the ability to cache external data into RDDs/DataFrames.
Technical Performance Advantage: The distributed nature of Spark and the advanced optimization capabilities make it the superior choice for complex data transformation (ETL/ELT) and high-performance, parallel execution.
The Modern Evolution: The Open, AI-Ready Lakehouse
The limitations of the traditional comparison—specifically around governance and interoperability—are driving the industry toward the Open Lakehouse architecture.
The recommended cutting-edge solution is anchoring your data strategy with BigQuery BigLake and the Apache Iceberg open table format.
By adopting this approach, you eliminate the "either/or" choice:
- Unified Governance: BigQuery BigLake acts as a central control plane. It enforces a single set of security and access policies (including row-level security) on your GCS data. This policy is then respected by all engines, including BigQuery and Databricks.
- True Interoperability: Your data is stored once in the open Iceberg format. This single copy can be accessed and written to by both BigQuery (for BI) and Databricks' Spark engine (for AI/ML), breaking vendor dependencies.
This is the secure, flexible, and fully governed foundation for an AI-native enterprise—ready for the next wave of agentic and predictive workflows.