Data Mesh: The Future of Decentralized Data Architecture

What is data mesh
Data mesh is a decentralized data architecture that organizes data ownership by business domain. It reduces dependency on a centralized data team, accelerating data delivery for reporting, analytics, and advanced use cases like Artificial Intelligence and Machine Learning (AI/ML).
Data mesh organizes the entire data lifecycle—ingestion, processing, and serving—around business domains. For example, a Sales domain team will own and manage the specific data attributes they need (e.g., customer buying patterns in a specific region).
Data mesh is often compared to microservices architecture, as both promote decentralization, autonomy, and loosely coupled modules built around specific business capabilities.
Why do we need data mesh
In small organizations, a centralized data team can efficiently manage data requirements. However, as the company scales, this model quickly becomes a bottleneck. The central team struggles to keep up, needing to constantly learn new domains, integrate diverse data sources, apply complex business logic, and rapidly scale infrastructure—all of which significantly slows down data delivery.
The data mesh model solves this by distributing data ownership to the domain teams, moving away from relying solely on centralized ETL/ELT pipelines. Domain teams manage their data end-to-end and publish it to the organization as easily discoverable data products, often via API services.
This shift frees the central data team from the constant, time-consuming effort of learning new domain intricacies and integrating new sources. They can now refocus on platform enablement, improving infrastructure, automating manual tasks, and increasing overall data pipeline reliability and efficiency.
Core principles of data mesh
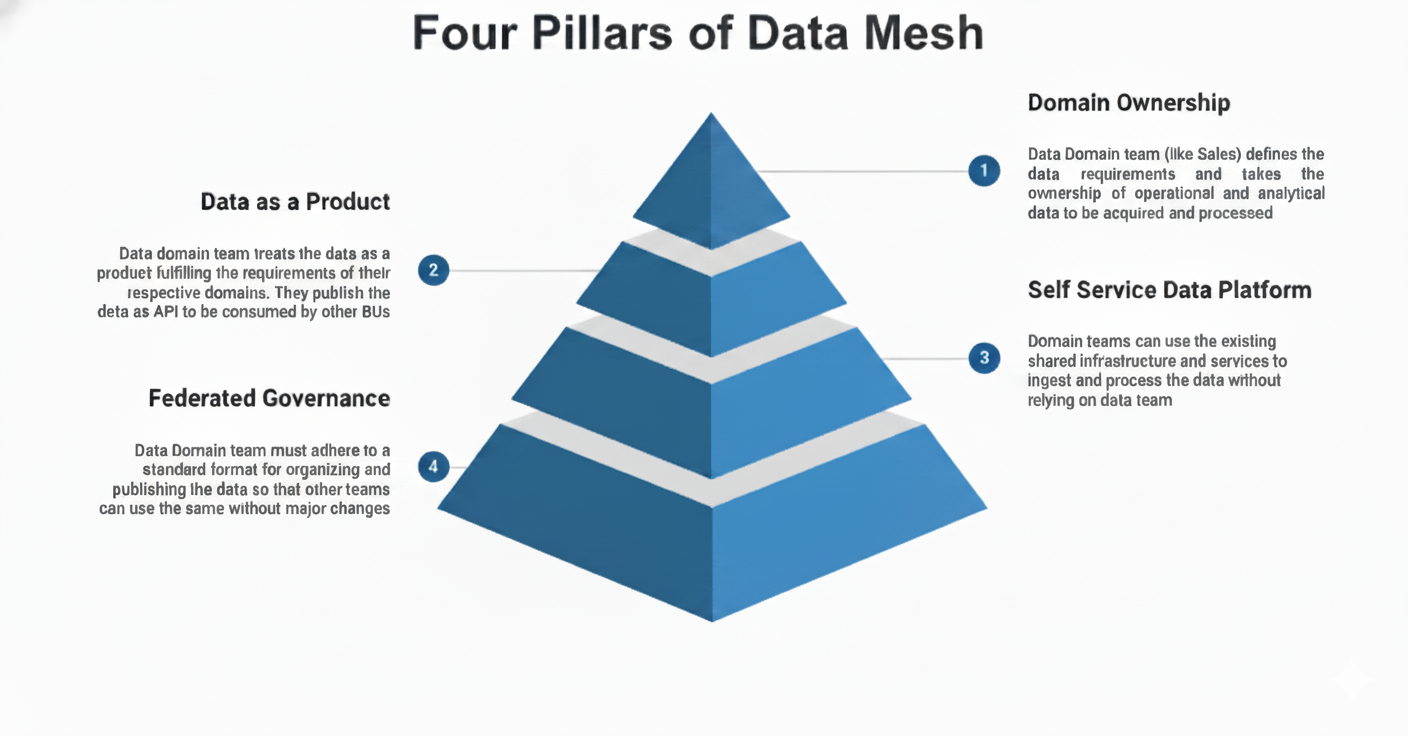
There are 4 pillars of data mesh:
-
Domain-oriented decentralized data ownership
Traditionally, the centralized data team would take business requirements, create design documents, and execute the ETL strategy. In the data mesh architecture, ownership shifts to the domain team.
Domain teams define their own data pipelines (covering alerts, error handling, and logging) to acquire and transform data into a presentable format. They are also responsible for making the data available to other teams through an API. The choice of tools and technologies lies with the particular domain team (in adherence to organization policies).
The central data team is no longer the sole owner of the dataset; they are responsible only for defining the organization's high-level data policies and maintaining the overall platform.
-
Data as a product (discoverable, trustworthy, usable)
This principle shifts the mindset of the people from just the ETL part of the data architecture to viewing the data as a logical unit which comprises the complete lifecycle of the data and fulfills the business requirements of a particular domain.
This approach allows the domain team to define their own set of security requirements, code standardization and policies to store, archive and purge the data. The flexibility of defining their own specification comes with the added responsibility of publishing the data to the outer world through a public API just like a product that is trustworthy and usable.
An example of the approach is - Bigquery having certain datasets belonging to a particular domain, say Marketing. This team will define and execute the strategy to populate the tables inside these datasets and will also define the roles to be given to other domains on those datasets so that they can also explore those datasets without putting efforts to maintain these tables.
-
Self-serve data infrastructure platform
This principle talks about the capabilities that a domain team needs to acquire and process the data. In the early days, the central team used to create data pipelines for end to end flow of data. The domain team used to wait for the landing of the data in the final / curated layer. But with the implementation of the principle of Self-serve data infrastructure, domain teams can use the existing shared tools, services, infrastructure and data pipelines for data ingestion, storage & processing, discovery and cataloging, security and governance and finally monitoring and observability.
In other words, it can be called as “Data Platform as a service (DPaaS)”.
-
Federated computational governance
While the complete lifecycle of the data is managed by the domain teams, the data governance team comes from the centralized data team only. As a part of governance, they define the policies for standardization, overall security and documentation for the data to be shared with the other teams.
In order to bring the standardization in organization, the centralized team defines a “data contract”. A data contract is a document that establishes the structure, format, semantics, quality and terms & conditions of use of exchanging data between data provider and data consumer. Once the data contract is filled by the domain team, it is shared with other domain teams so that the data is discoverable. An example of data contract is given below -
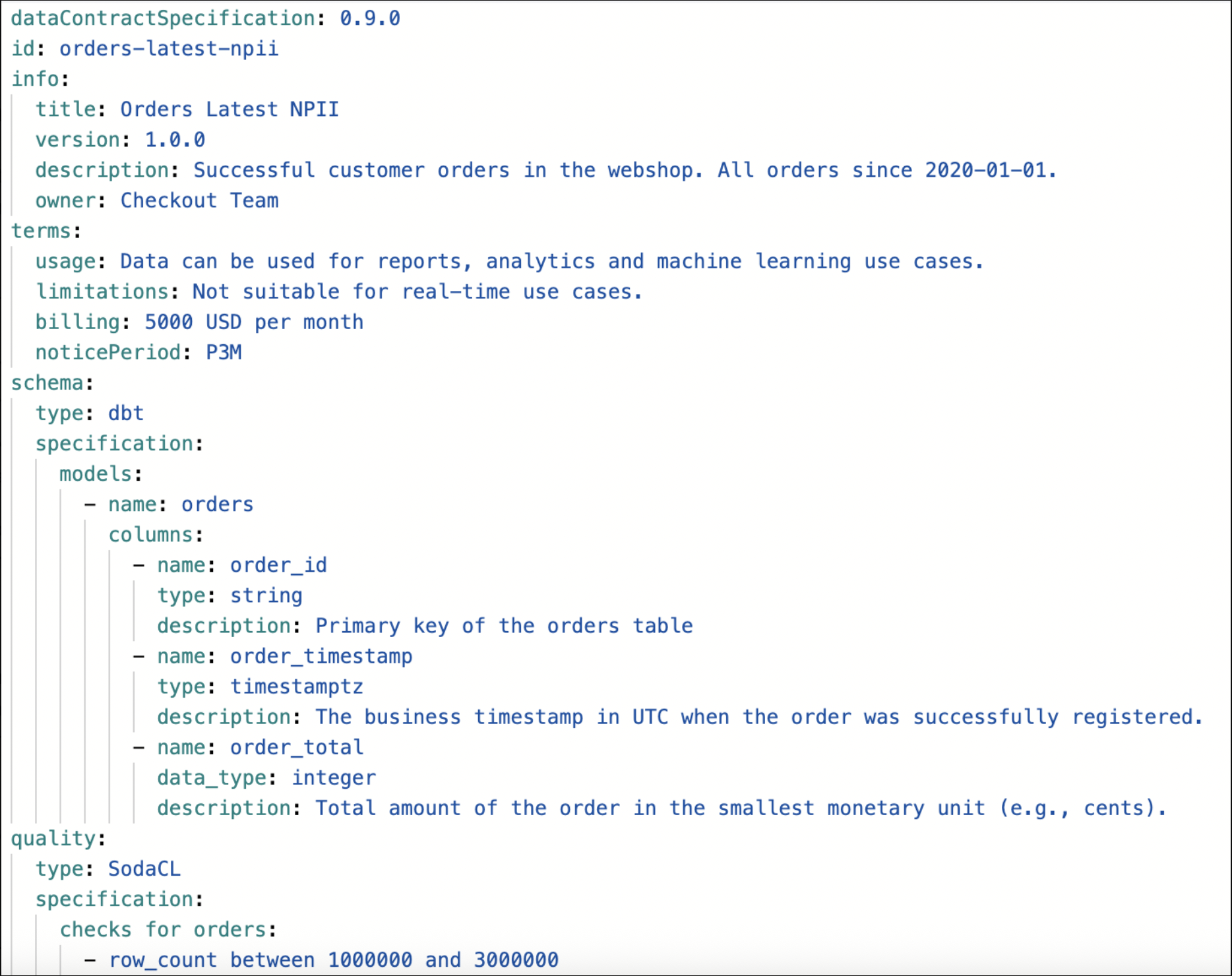
Data mesh architecture
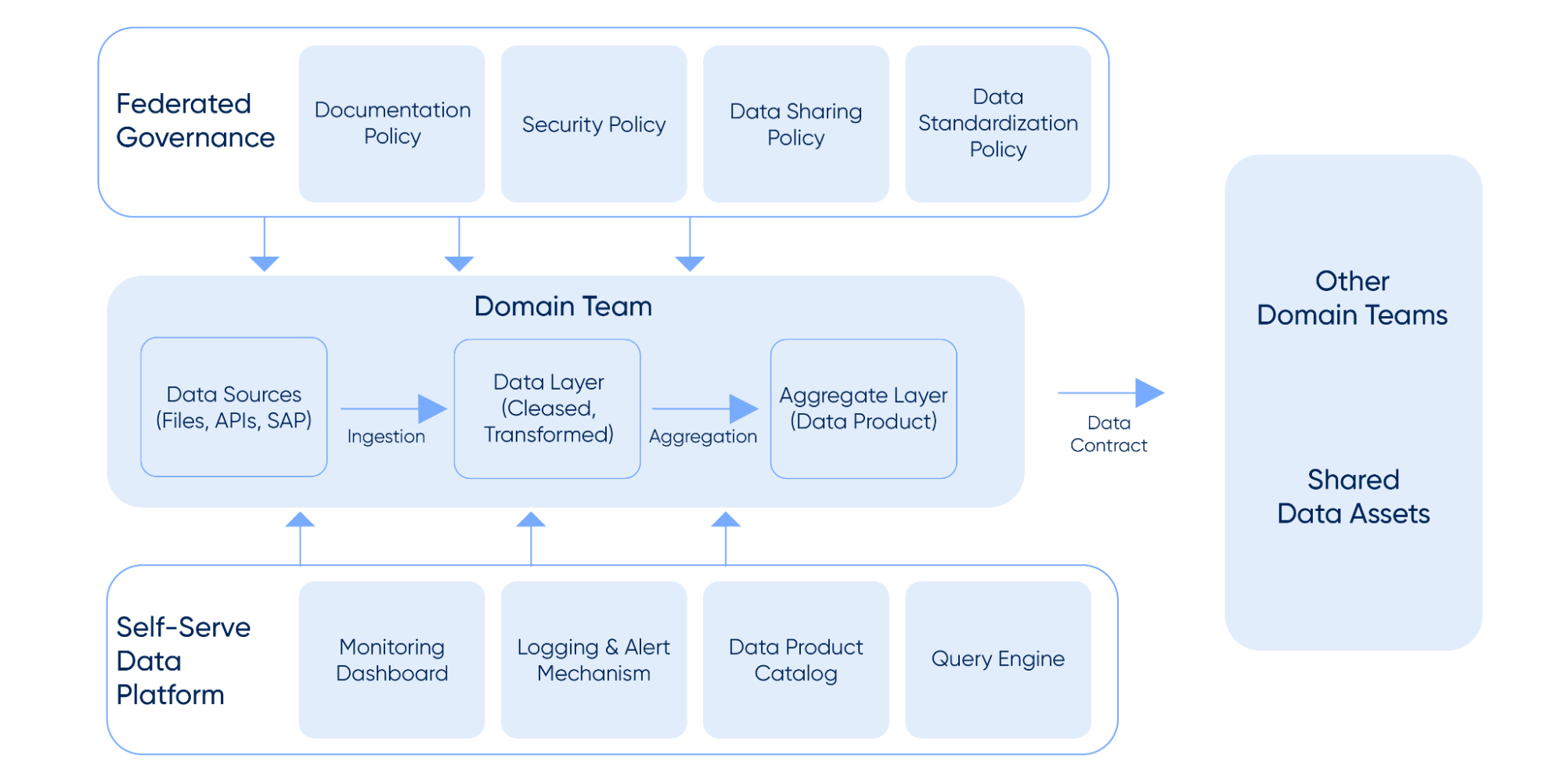
Challenges in adopting data mesh
While data mesh architecture helps the organization to remove the dependency on the centralized data team and has other advantages also, it has its own set of challenges which needs to be addressed. These are:
-
Losing the golden copy of truth
Once the domain teams start working on acquiring the data they need for their respective function (without having the sight of another domain’s data acquisition process), there are pretty good chances that the single, central and authoritative repository of organization's data is lost. The discovery of what entities / attributes of data has been explored by any team happens in the last phase of the life cycle of data and by what time the same data (may be from different sources) has already been processed by another team. There may be different versions of data available with the different teams depending upon their frequency of refreshing the data.
Domain teams may lose the trust of the business units for their data requirements as different domains may have different versions of the same data.
-
Ownership and data governance challenges
One of the biggest challenges in any decentralized approach is the ambiguity over ownership boundaries. In data mesh, there can be confusion about which team covers what aspects of data governance. For example, a domain team might set up data lineage only up to their boundary, while the central governance team is interested in tracking lineage across all domains. Similarly, data quality standards defined by one domain may not align with those of the organization as a whole.
-
Additional cost
Whenever an organization moves from the current data architecture to new, improved and efficient data architecture, there is always the cost of migration involved. Once the migration is done, the domain team requires more technical people to support the current infrastructure, data pipelines and cater to the future data requirements. This will add to the budget of the domain team. The data services or resources which were being shared earlier by the centralized team have to be duplicated for different domain teams which would incur extra cost to the organization.
-
Cultural shift
For a long time, the organizations have been dependent on the centralized data team to gather the requirements from the business units and bring the necessary data from various teams. Now, before the discussions and workshops start on passing the ownership to the domain team, it becomes necessary for the domain team to accept the responsibility of not only defining the use-cases, but also bring the relevant data. The domain teams also have an additional responsibility of publishing the data through public APIs.
On the other hand, since the control of the data goes away for the centralized data team, they may feel insecure, less occupied and undervalued in the organization. Hence, they may not support the transition of ownership.
Benefits of data mesh
The adoption of data mesh brings a lot of benefits to the organization. Some of the benefits are:
-
Less time for new data acquisition
With the implementation of data mesh architecture, the domain team does not need to spend time and effort explaining their data requirements to the centralized data team. In the complete lifecycle of the data, some steps like converting business requirements into technical documents, performing UAT can be avoided now as the domain team is directly involved in the data acquisition process. This reduces the overall time it used to take to bring the data for the usage by other business units.
-
Stronger security and compliance
The centralized team may be knowing the nitty gritty of data, but they lack the strong domain knowledge. This is especially true in highly specialized industries with unique complexities, like finance and healthcare, where the security of PII data is of utmost importance. Failing to adhere to compliance may lead to financial and reputational losses.
The domain teams have a better understanding of the compliance they need to adhere to. So, based on the compliance requirements, they are able to define the data retention, purging and archiving policies more efficiently.
-
Enhanced interoperability
Whenever an organization moves from the current data architecture to new, improved and efficient data architecture, there is always the cost of migration involved. Once the migration is done, the domain team requires more technical people to support the current infrastructure, data pipelines and cater to the future data requirements. This will add to the budget of the domain team. The data services or resources which were being shared earlier by the centralized team have to be duplicated for different domain teams which would incur extra cost to the organization.
-
Cultural shift
Data mesh fosters interoperability by requiring domains to adhere to agreed-upon standards for data structures, formats, and API interfaces. This standardization is formalized through a data contract, which ensures that all data products can be easily consumed by other teams across the organization.
-
Reduced bottlenecks
Traditionally, the organizations used to rely heavily on the centralized data team for their data requirements. Initially, when the organization is small, this team meets such demands very effectively, but when the scale of operations grows, the same data team may become a bottleneck. They may not be able to scale at the same level (in terms of numbers and effectiveness), which may lead to an increase in wait time for meeting the data requirements.
With the adoption of data mesh architecture, the dependency on the centralized team is reduced. The domain team takes the ownership of data acquisition for their respective business units. Since the domain teams are focused on their respective modules, their data requirements are very restricted. This reduces the overall life cycle of data and business units do not wait for too long.
Conclusion
In today's world, where the need for data has grown exponentially and the centralized data teams are over burdened, data mesh architecture brings a ray of hope by transferring the ownership to the domain teams.
By decentralizing the data ownership and empowering the domain teams, the organizations are bringing a new dimension to the data which is called data-as-a-product culture and transforming traditional monolithic data platforms into a federation of interoperable, domain-aligned pipelines and datasets.
When executed with the right infrastructure abstractions (e.g., Databricks Unity Catalog, Snowflake domains, or Google Cloud Data Products) and governance automation, data mesh enables scalable, reliable, and evolvable data architectures — turning data into a first-class engineering product rather than an afterthought.