Breaking down silos in R&D: How we built a unified Enterprise Agent for Biotech
Authors:
Anmol Jain, Lead Solutions Consultant, Searce
Monark Unadkat, Senior Machine Learning Architect, Searce
With MCP, Dynamic Routing, and Multi-Source Search
Modern research and development (R&D) relies on a massive web of highly specialized software. This is especially true in biotech and pharma, where a typical team is constantly juggling a dozen different platforms:
- Lab notes & samples: Tracking experiments and biological records (think Benchling, ELNs or LIMS)
- Massive data files: Genomics, proteomics, and imaging files that need to talk to each other
- Computational infrastructure: Code pipelines, ML model registries, GPU job logs, and data warehouses (GitHub, MLflow, Snowflake)
- Molecular design tools: Protein structure databases and simulation results
- Clinical & regulatory documents: Trial management, regulatory filings, and electronic data capture
While each of these tools is great at its specific job, together they create a frustrating game of digital hide-and-seek.
To understand the full context of an experiment, scientists have to jump between five different tabs and manually piece information together. Answering basic questions turns into an exhausting cycle of manual lookups:
- "What's the current status of this project?"
- "Which pipeline processed this sequencing run?"
- "Where is the analysis notebook associated with this dataset?"
Every minute spent hunting down data is a minute stolen directly from actual, life-saving science.
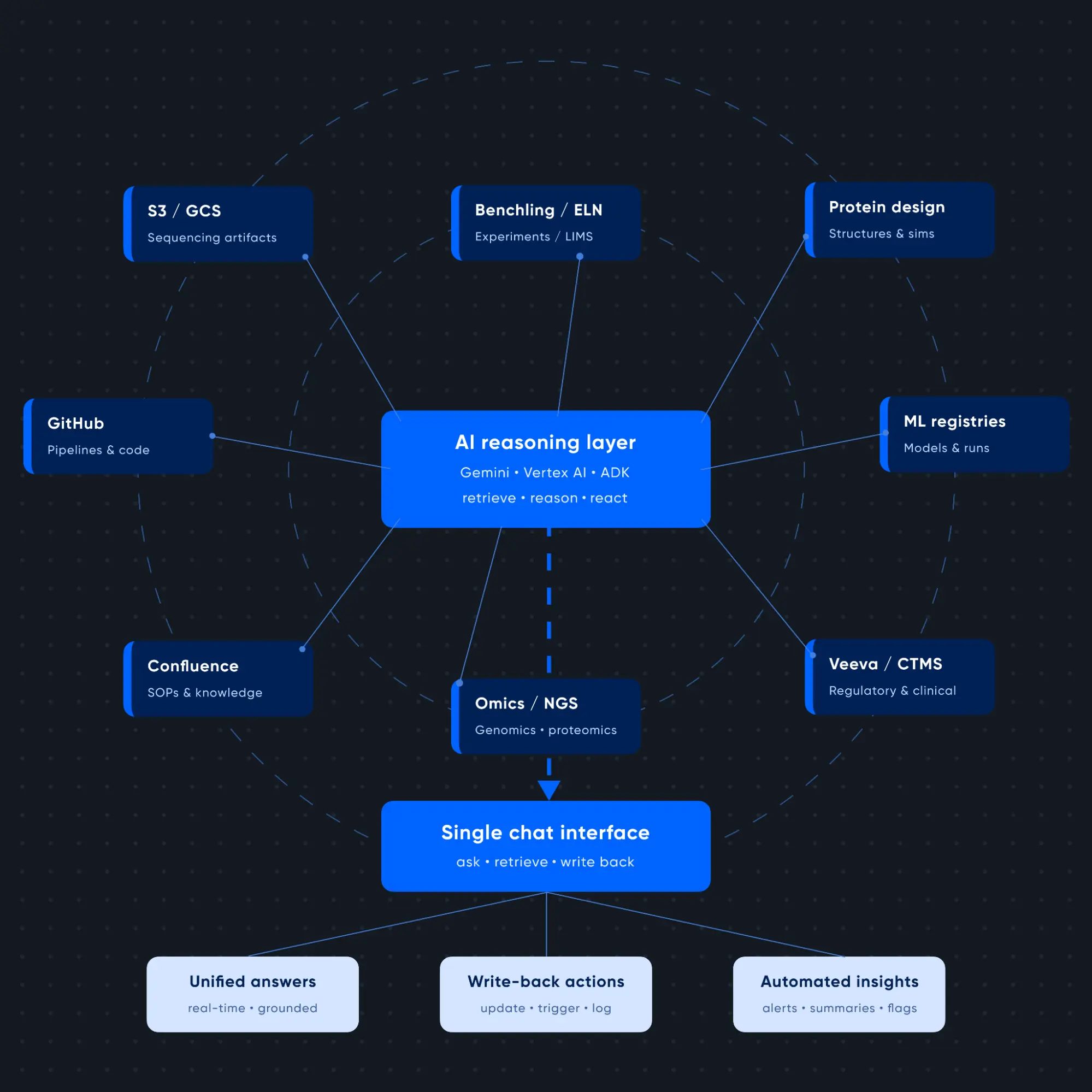
What we built
Searce recently partnered with an AI-native biotech organization that uses generative models to design novel proteins and antibodies.
Their immediate need was clear: unify the backbone of their NGS (gene sequencing) experiment lifecycle across three primary sources:
- Benchling for lab notes and biological design
- GitHub for the analytical pipelines and computational notebooks processing the data
- S3 where the actual sequencing data and analysis files live
We built an agentic AI assistant on Google Cloud that turns a single chat window into an R&D command center. Now,researchers can ask questions in natural language, get an unified answer pulled from all three systems in real time, and act on them instantly with write-back to the source. No tab-switching. No manual reconciliation.
"Searce consistently demonstrates the deep GCP expertise required to solve complex data challenges. By leveraging the Gemini Enterprise Agent Platform to unify data across Benchling, GitHub, and S3, Searce delivered a seamless solution that drove rapid time to value for our joint customer in the biotech industry."
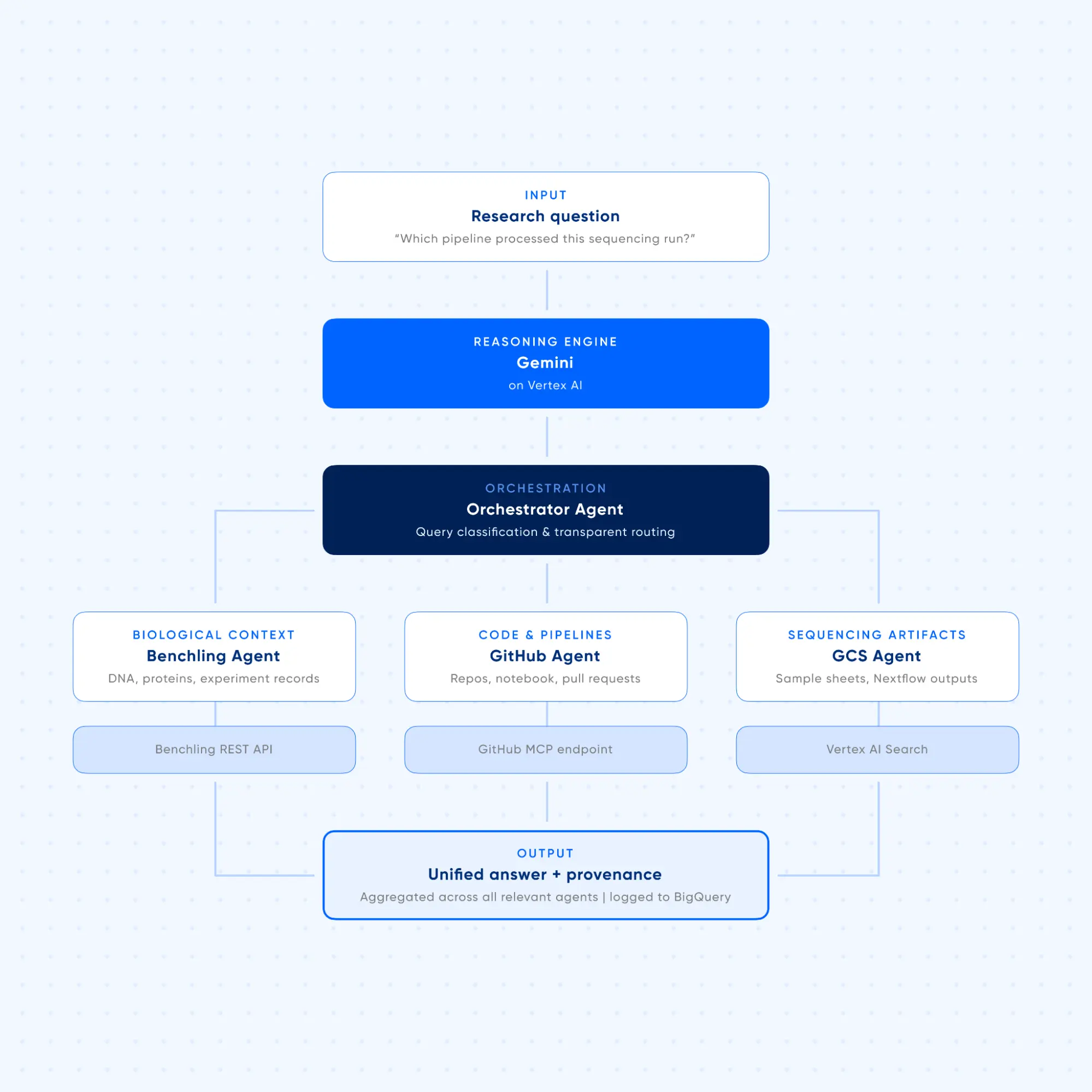
How it works
The system is a multi-agent workflow built on Google Agent Development Kit (ADK), deployed on Vertex AI, with Gemini as the reasoning engine.
At the center sits an Orchestrator Agent, a transparent router that receives a user's question, identifies which specialized agents are relevant, forwards the request without distorting its intent, and assembles a unified response. Critically, it controls API calls and cost by only invoking what's needed.
Three specialized agents sit beneath it:
- Agent 1(Biological Context): Reaches out to authoritative experimental records and molecular metadata via native Benchling REST APIs
- Agent 2(Code Intelligence): Interacts with GitHub repositories through a standardized MCP.
- Agent 3 (Sequencing Artifacts): Perform semantic retrieval over unstructured artifacts and notebook outputs, indexed for semantic retrieval (S3, GCS)
Best of all, every single tool call, routing path, and orchestration decision the AI makes is automatically logged. In regulated or IP-sensitive research, having a fully traceable, verifiable audit trail for reproducibility isn't optional, it's a must.
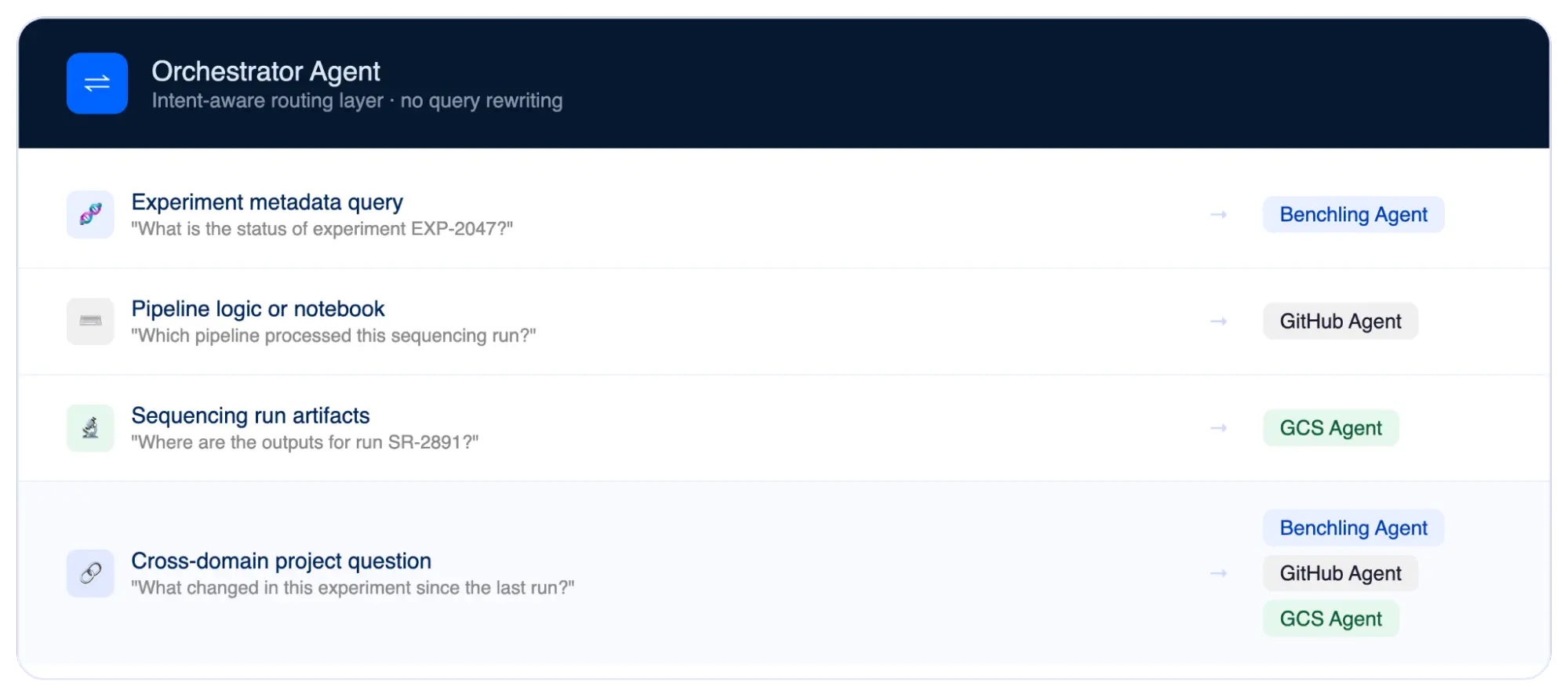
The design pattern that makes it work
The biggest reason enterprise AI projects fail is that companies treat every question the same way. We avoided this by architecting specialized access routes tailored to different query types.
By relying on model-driven routing to dynamically classify a user's intent, the Orchestrator keeps the system highly flexible while preserving a clear, explicit boundary between specialized capabilities.
A production-grade enterprise agent does not just search well, it knows exactly where to search. This matters because not every query should blindly fan out everywhere.
To optimize this blueprint, the system maps queries into three distinct data pathways based on intent:
- Operational access: for questions needing the absolute latest, up-to-the-second status.. The AI reaches directly into the live system.
- Warehouse access: for historical trends, comparisons, rollups, trend analysis, and reporting. The AI looks at a broader data warehouse so it doesn't slow down live tools.
- Event-triggered access: for change awareness. When a sequencing run finishes or a new dataset drops, the system instantly alerts the right people.
One pattern per question type. No overloading systems of record for analytical queries. No stale answers for operational ones.
Business outcomes
By automating these tedious lookups, the projected impact is massive:
- 70% reduction in time spent gathering experiment context, queries that previously required manual lookup
- NGS metadata collection workflows compressed from ~2 - 3 hours of manual compilation to under 5 minutes
- 100% of agent actions logged to BigQuery, full audit trail for every query, routing decision, and source touched, with zero additional compliance overhead
- New data source onboarding projected at days rather than weeks, thanks to the modular agent architecture
- ~30% reduction in cross-team coordination overhead between wet lab scientists and computational teams, who now share a single interface instead of exchanging manual summaries
Four Takeaways for Any Industry
Even if you aren't in biotech, these rules apply to any complex business:
- Fix the data layout before the AI. A basic, surface-level AI tool cannot fix fundamentally disconnected data infrastructure. You must architect a system that can retrieve and connect information across multiple domains simultaneously.
- You need a common language. In our case, unique Experiment IDs were the glue holding Benchling, GitHub, and S3 together. Without shared identifiers, an AI can only give you isolated facts, not real context.
- Standardization helps, but only when applied thoughtfully. Protocols like MCP cleanly expose complex repository operations as agent tools, but they shouldn't be forced onto every legacy system.
- Routing matters just as much as retrieval. A resilient enterprise agent must protect source systems from expensive, broad "fan-outs." Implementing model-driven classification rather than brittle, hardcoded rules ensures queries are targeted dynamically.
Interested in building a unified AI reasoning layer across your R&D systems? Get in touch with the Searce team.